- Published on
ChatGPTの会話履歴をJSONで出力し整形 #JavaScript #MDX
- Authors
- Name
- Shou Arisaka nyapp.buzz/shou
- short bio
- Z世代の情報技術者。Next.jsで自作SNSを個人開発中。


ChatGPTで会話の履歴を保存する方法は最もメジャーなものとしてビルトインで用意されている公式機能、「データコントロール」タブを→「エクスポート」によるバックアップの方法があると思います。
僕自身も以前はこの方法で会話履歴を保存していて、その中のJSONファイルを利用してデータを抽出する方法を取っていましたが、これには問題…というか面倒な点があります。
- 全部の会話履歴をエクスポートするので、zipファイルの添付されたメールがOpen AIから届くのが遅い。
- 一日に何度もはできない。都度エクスポートの操作、メール確認、ダウンロード、解凍、ファイルの確認、という一連の流れが冗長。
- 全部の会話履歴がエクスポートされるので、場合によってはメモリが足りない(Node.jsなら
JavaScript heap out of memory的なエラー)状態になりやすい。 - だからもちろん処理も重いしコードも長くなる。処理に冗長な認知リソースが割かれる。
結局のところ、必要な一つの会話の履歴だけを取り出すのではなく全部を都度取り出して処理してっていうのが色々な側面で時間を取ってしまう(コンピュータリソース的にも人的リソース的にも)というのが主問題です。
これに対処しよう、とChromeデベロッパーツール(開発者ツール)とJavaScriptでシンプル・スマートに抽出・データ整形(例えばMDX形式の配列にするとか)までしてしまおうというのが今回の記事の趣旨となります。

蛇足
Google Chromeでは拡張機能ストアで「Save ChatGPT」(現在は利用不可になっているみたい)や「ChatGPT to Markdown」といったChatGPTのエクスポート・履歴の保存に特化した拡張機能がいくつかあるようです。
これらで用途に間に合うのであれば、今回の記事で紹介するJavaScriptによる抽出方法は必ずしも必要ではないでしょう。
具体的方法
ChatGPTで任意のページを開いたら、そこでChromeデベロッパーツールを開いてください。
以降のステップは以下となります。
以下は具体的なJavaScriptコードの例です。titleとcontentのフォーマットでオブジェクトの配列にしています。
[購読で表示されます]
.map(a => a?.content.parts).flat().filter(a => a).map(a => a.match(/### (.*)\n\n([\s\S]+)/m)).filter(a => a).map(a => { return { title: a[1], content: a[2] }})
これで綺麗に取得できました。
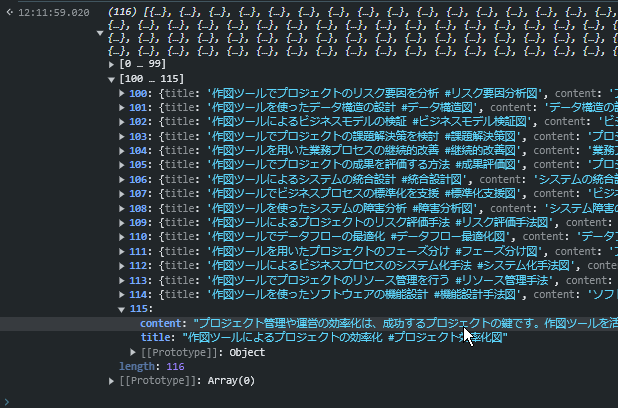
(おまけ) これをMDX形式に変換もしてみます。ついでにファイルに保存してしまいましょう。
// 上記の結果を変数objに格納していると想定
// the summary is the first paragraph of the content
obj.map(a => `---\ntitle: '${a.title}'\ndate: ${new Date().toISOString().split('T')[0]}\nlastmod: ${new Date().toISOString().split('T')[0]}\ntags: [作図ツール, AI-assisted]\ndraft: false\nsummary: '${a.content.match(/(.+)\n\n/)[1]}'\nimages: []\n---\n\n${a.content}`).forEach((a, i) => {
// save as a file, on browser
const blob = new Blob([a], { type: 'text/plain' });
const url = URL.createObjectURL(blob);
const aTag = document.createElement('a');
aTag.href = url;
aTag.download = `chatgpt-${i}.mdx`;
aTag.click();
URL.revokeObjectURL(url);
});
(上記コードはテストしていないため、場合によって動作しない可能性があります)
以上、ChatGPTの会話履歴をJavaScriptとChromeデベロッパーツールを使ってJSONで出力して任意の形に整形する方法でした。
Node.jsで続きの処理を行う (追記)
ちょうどこの記事を書きながらNode.jsで軽く書いてみたのでシェアします。
(async () => {
const objRaw = fs.readFileSync(`${process.cwd()}/obj.json`, 'utf8');
const obj = JSON.parse(objRaw);
const mdx_strings = obj.map((item) => {
return `---
title: ${item.title}
date: ${new Date().toISOString().split('T')[0]}
lastmod: ${new Date().toISOString().split('T')[0]}
tags: [作図ツール, AI-assisted]
draft: false
summary: ${item.content.match(/(.+)\n\n/)[1]}
images: []
---
${item.content}`
}
).join("\n\n\n\n");
// split by \n\n\n\n+
const mdx_array = mdx_strings.split(/\n\n\n\n+/);
// ...省略
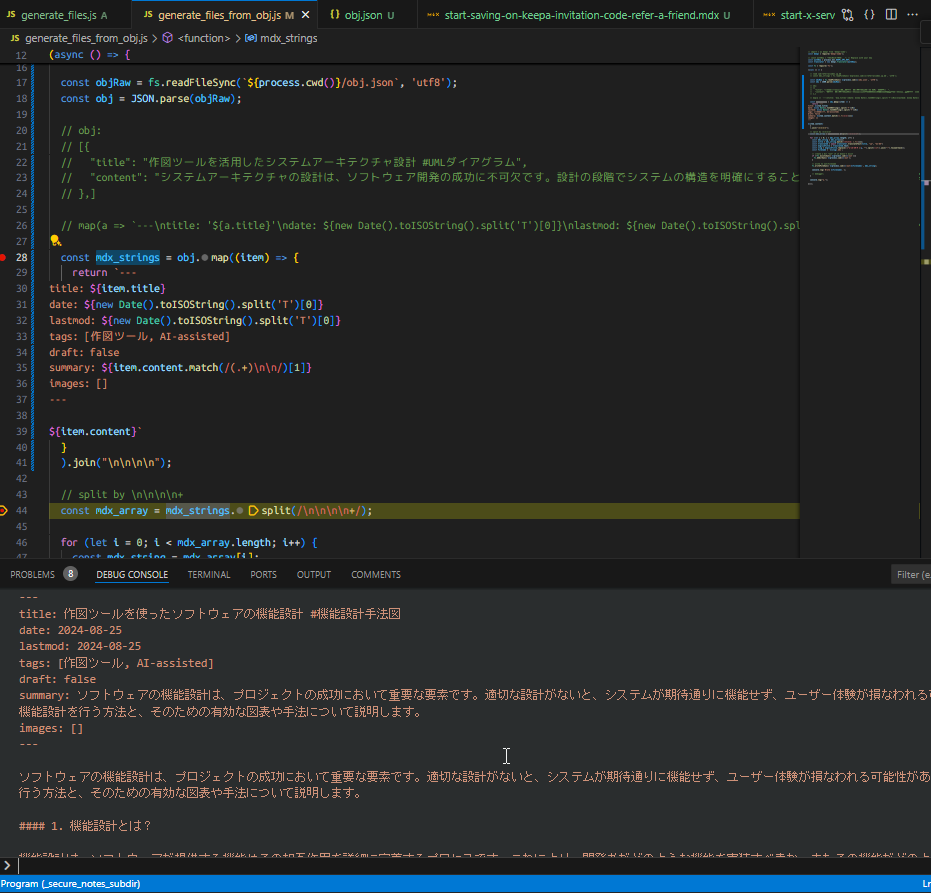
MDXによるサイト記事作成の面倒なところは、ファイル名(URLスラッグ・slug)を考えて設定しないといけないところです。
そこで最近は、deeplのapiで自動化してしまっています。
deeplについて最近書いた記事もご参考にどうぞ: DeepL APIでglossaryを作成して翻訳結果を指定する #Node.js
Node.jsプログラム:
- "deepl-node": "^1.13.0"を使っています。
- node.jsのバージョンはv22.5.1ですが、v16.6.0以降であれば問題なく動作すると思います。
タイトルを英語に翻訳してファイル名とし、mdx形式のファイルで保存していっている動作:

2分くらい終わるのを待っていると、120記事くらいのmdxファイルを先程のtitleとcontentのオブジェクト配列を元に作成できました。

ChatGPTに関わるご依頼も受け付けています
- ChatGPTの生成文章を整形したい(テキスト、CSV、スプレッドシート、JSON、HTML、Markdownなど)
例えば以下のように、ChatGPTの生成結果は会話ごとでランダムなため、いつでも"##"のタイトルから始まるわけではありません。
こういった非定型的、非形式的な出力にもJavaScriptやNode.js、Pythonでデータ処理の対応が可能です。
もちろん、ChatGPTの生成文章を整形するだけでなく、ChatGPTを使ったアプリケーションの開発も受け付けています。
今回の記事のように、ChatGPTやAIツール(Phind、Perplexity、Claudeなど)の作業効率化・自動化に関するご相談もお気軽にどうぞ。
費用は一律で3000円/30分となります。(繁忙期にはご対応の難しい場合がありますため、事前のご予約やご相談をお願いいたします。)
クレジット(デビット)・Apple Pay・Google Pay・コンビニ払いに対応しています。
※「支払う」ボタンを押すまで、お引き落としはされません。
ご購入に際しては、有料コンテンツ利用規約・購入規約・返金規約をよくお読みいただき、ご同意の上でお進みください。
友達紹介プログラムもやっています。(紹介した人に20%、紹介された人にも20%)
タップで詳細を以下に表示します


15歳でWordPressサイトを立ち上げ、ウェブ領域に足を踏み入れる。翌年にはRuby on Railsを用いたマイクロサービス開発に着手し、現在はデジタル庁を支えたNext.jsによるHP作成やSaaS開発のプロジェクトに携わりながら、React.js・Node.js・TypeScriptによるモダンなウェブアプリの個人開発を趣味でも行う。
フロントエンドからバックエンドまで一貫したアジャイルなフルスタック開発を得意とし、ウェブマーケティングや広告デザインも必要に応じて担当、広告運用・SEO対策・データ分析まで行う低コストかつ高品質な顧客体験の提供が好評。
国内外から200万人を超える人々に支えられ、9周年を迎えるITブログ「yuipro」の開発者、デザイナーでありライター。現在ベータ段階の自作SNS「nyapp.buzz」を日本一の国産SNSとするべく奮闘中。








